Scalability is a crucial aspect of system design, especially in today’s world of rapidly growing data and user bases. As applications and services become more popular, they must be able to handle increased traffic and data without compromising performance or reliability. In this article, we will explore what scalability is, why it is important, and how to achieve it in system design. The truth is, many of us don’t dive deep enough into scalability to truly grasp its significance in system design. Consequently, we fail to impress interviewers who are looking for candidates with a comprehensive understanding of this crucial aspect.
System Design - Scalability
Running a system for one user is significantly different from running it for 10,000 users and that too is different from running it for 1 million users. As the system grows the performance starts to degrade unless we adapt it to deal with that growth. Scalability is the property of a system to handle a growing amount of load by adding resources to the system. A system that can continuously evolve to support a growing amount of work is scalable.
Importance of Scalability in System Design
Scalability is crucial in system design for several reasons:
- Handle Growth: Scalability ensures that a system can handle growth in terms of user base, data volume, and traffic without experiencing a significant decrease in performance or reliability. This is essential for businesses that aim to expand their operations and reach a larger audience over time.
- Improve Performance: Scalability can improve the overall performance of a system by distributing the workload across multiple resources or servers. This can reduce response times, increase throughput, and enhance the user experience.
- Ensure Availability: Scalability can improve the availability of a system by ensuring that it can withstand failures or spikes in traffic without becoming unavailable. This is critical for mission-critical systems that need to be available 24/7.
- Optimize Costs: Scalability can help optimize costs by allowing resources to be scaled up or down based on demand. This can reduce the need for over-provisioning resources, leading to cost savings.
- Support Innovation: Scalability can support innovation by enabling the development of new features or services without being constrained by the limitations of the existing infrastructure. This can help businesses stay competitive and adapt to changing market demands.
How can a System Grow?
A system can grow in several dimensions.

1. Growth in User Base
More users started using the system, leading to increased number of requests.
Example: A social media platform experiencing a surge in new users.
2. Growth in Features
Introducing new functionality to expand the system's capabilities.
Example: An e-commerce website adding support for a new payment method.
3. Growth in Data Volume
Growth in the amount of data the system stores and manages due to user activity or logging.
Example: A video streaming platform like youtube storing more video content over time.
4. Growth in Complexity
The system's architecture evolves to accommodate new features, scale, or integrations, resulting in additional components and dependencies.
Example: A system that started as a simple application is broken into smaller, independent systems.
5. Growth in Geographic Reach
The system is expanded to serve users in new regions or countries.
Example: An e-commerce company launching websites and distribution in new international markets.
How to Scale a System?
Here are 2 common ways to make a system scalable:
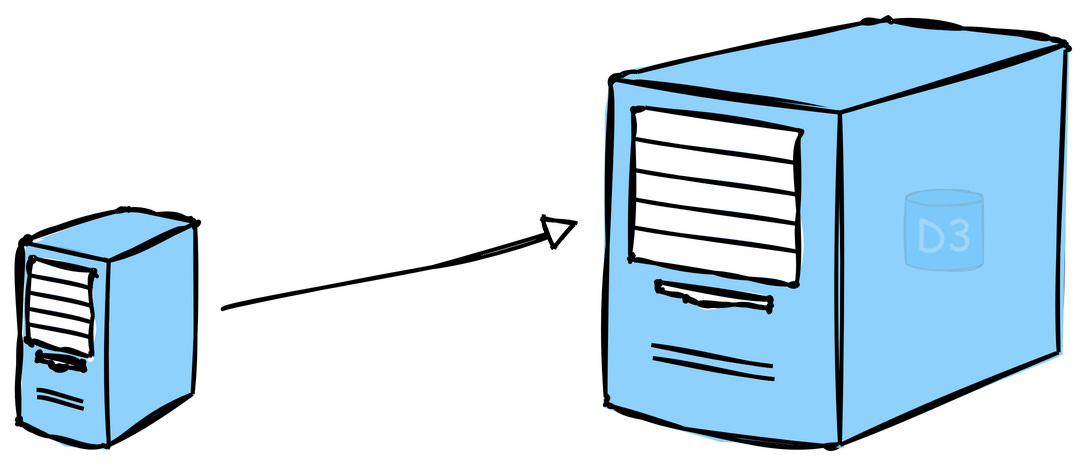
1. Vertical Scaling (Scale up)
This means adding more power to your existing machines by upgrading server with more RAM, faster CPUs, or additional storage. It's a good approach for simpler architectures but has limitations in how far you can go.
Advantages of Vertical Scaling
- Increased capacity: Upgrading the hardware of a server can improve its performance and increase its capacity to handle incoming requests.
- Easier management: Vertical scaling typically involves upgrading a single node, which can be less complex than managing multiple nodes.
Disadvantages of Vertical Scaling
- Limited scalability: Vertical scaling is limited by the physical constraints of the hardware, whereas horizontal scaling can be easily expanded by adding more nodes.
- Increased cost: Upgrading the hardware of a server can be more expensive than adding more nodes.
- Single point of failure: All incoming requests are still directed to a single server, which increases the risk of downtime if the server fails
2. Horizontal Scaling (Scale out)
This means adding more machines to your system to spread the workload across multiple servers. It's often considered the most effective way to scale for large systems.

Example: Netflix uses horizontal scaling for its streaming service, adding more servers to their clusters to handle the growing number of users and data traffic.
Advantages of Horizontal Scaling
- Increased capacity: More nodes or instances can handle a larger number of incoming requests.
- Improved performance: Load can be balanced across multiple nodes or instances, reducing the likelihood of any one server becoming overwhelmed.
- Increased fault tolerance: If one node fails, incoming requests can be redirected to another node, reducing the risk of downtime.
Disadvantages of Horizontal Scaling
- Increased complexity: Managing multiple nodes or instances can be more complex than managing a single node.
- Increased cost: Adding more nodes or instances will typically increase the cost of the system.
Remember: Scalable code is generally computation inefficient. It is bitter truth because we split big and complex code to a set of small associative operations so as to scale up horizontally because vertical scaling has a limit.
Vertical Scaling vs. Horizontal Scaling
Now that we have looked into the details of each type of scaling, let us compare them with respect to different parameters:
| Aspect | Horizontal Scaling | Vertical Scaling |
|---|---|---|
| Resource Addition | Adds more machines or servers to distribute workload | Enhances resources of individual components |
| Cost Effectiveness | Generally more cost-effective for large-scale systems | Initially simpler, but can become costlier long-term |
| Flexibility | Offers greater flexibility as it’s easier to add units | Limited flexibility, especially with hardware |
| Fault Tolerance | Enhances fault tolerance by distributing workload | Limited fault tolerance as it relies on a single unit |
| Performance | Performance can improve as workload is distributed | Performance may improve, but can hit hardware limits |
| Single Point of Failure | Less prone to single points of failure | Potential single points of failure due to one unit |
| Complexity | Can introduce complexity in managing distributed system | Simpler to manage as it involves fewer components |
| Applicability | Ideal for handling massive scalability needs | Suitable for moderate scalability requirements |
| Load Balancing | Requires load balancing mechanisms to distribute workload evenly across multiple units | Load balancing may be less critical as workload is managed by a single unit in most cases |
| Machine Communication | Horizontal scaling relies heavily on network communication to coordinate tasks and share data between distributed machines | Vertical scaling primarily involves interprocess communication within a single machine or between closely coupled processes, minimizing the need for network communication |
Factors Affecting Scalability
Below are the factors that affects the scalability with their explanation:
| Factors | |||
|---|---|---|---|
| Performance Bottlenecks | Performance bottlenecks are points in a system where the performance is significantly lower than expected. | These bottlenecks can be caused by various factors such as slow database queries, inefficient algorithms, or resource contention. | Identifying and addressing these bottlenecks is crucial for scalability, as they can limit the system’s ability to handle increased load. |
| Resource Utilization | Efficiently using resources such as CPU, memory, and disk space is essential for scalability. | Inefficient resource utilization can lead to bottlenecks and limit the system’s ability to scale. | Optimizing resource usage through efficient algorithms, caching, and load balancing can help improve scalability. |
| Network Latency | Network latency refers to the delay in transmission of data over a network. | High network latency can impact the scalability of distributed systems by causing delays in communication between nodes. | Minimizing network latency through efficient network design, caching, and optimizing data transfer can improve scalability. |
| Data Storage and Access | The way data is stored and accessed can impact scalability. | Using scalable data storage solutions such as distributed databases or caching mechanisms can improve scalability. | Efficient data access patterns, indexing, and data partitioning strategies can also help improve scalability |
| Concurrency and Parallelism | Concurrency refers to the ability of a system to handle multiple tasks or requests simultaneously. | Parallelism refers to the ability to execute multiple tasks or requests concurrently. | Designing for concurrency and parallelism can improve scalability by allowing the system to handle multiple tasks or requests simultaneously, thus improving throughput and reducing response times. |
| System Architecture | The overall architecture of the system, including how components are structured and connected, can impact scalability. | Using a modular, loosely coupled architecture that can be scaled horizontally (adding more instances) or vertically (upgrading existing instances) can improve scalability. | Monolithic architectures, on the other hand, can be less scalable as they may require scaling the entire system even if only a specific component needs more resources. |
Components that help to increase Scalabilty
Below are some of the main components that help to increase the scalability:
1. Load Balancing
Load balancing is the process of distributing traffic across multiple servers to ensure no single server becomes overwhelmed.
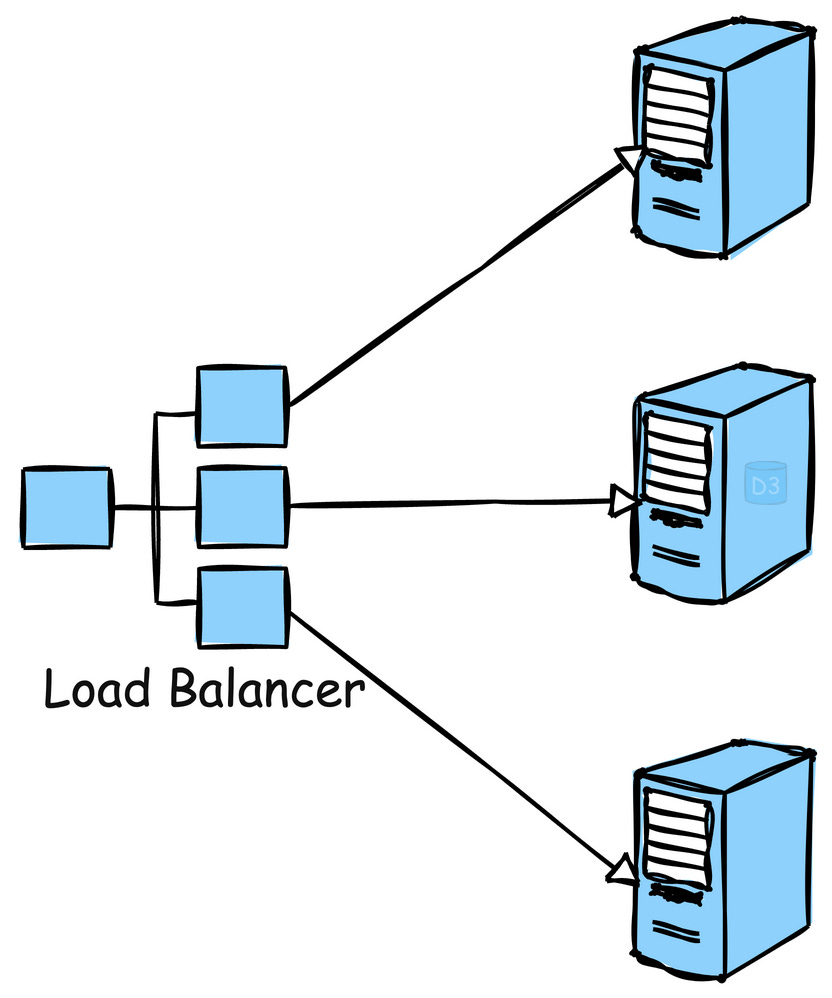
Example: Google employs load balancing extensively across its global infrastructure to distribute search queries and traffic evenly across its massive server farms.
2. Caching
Store frequently accessed data in-memory (like RAM) to reduce the load on the server or database. Implement caching can dramatically improve response times.
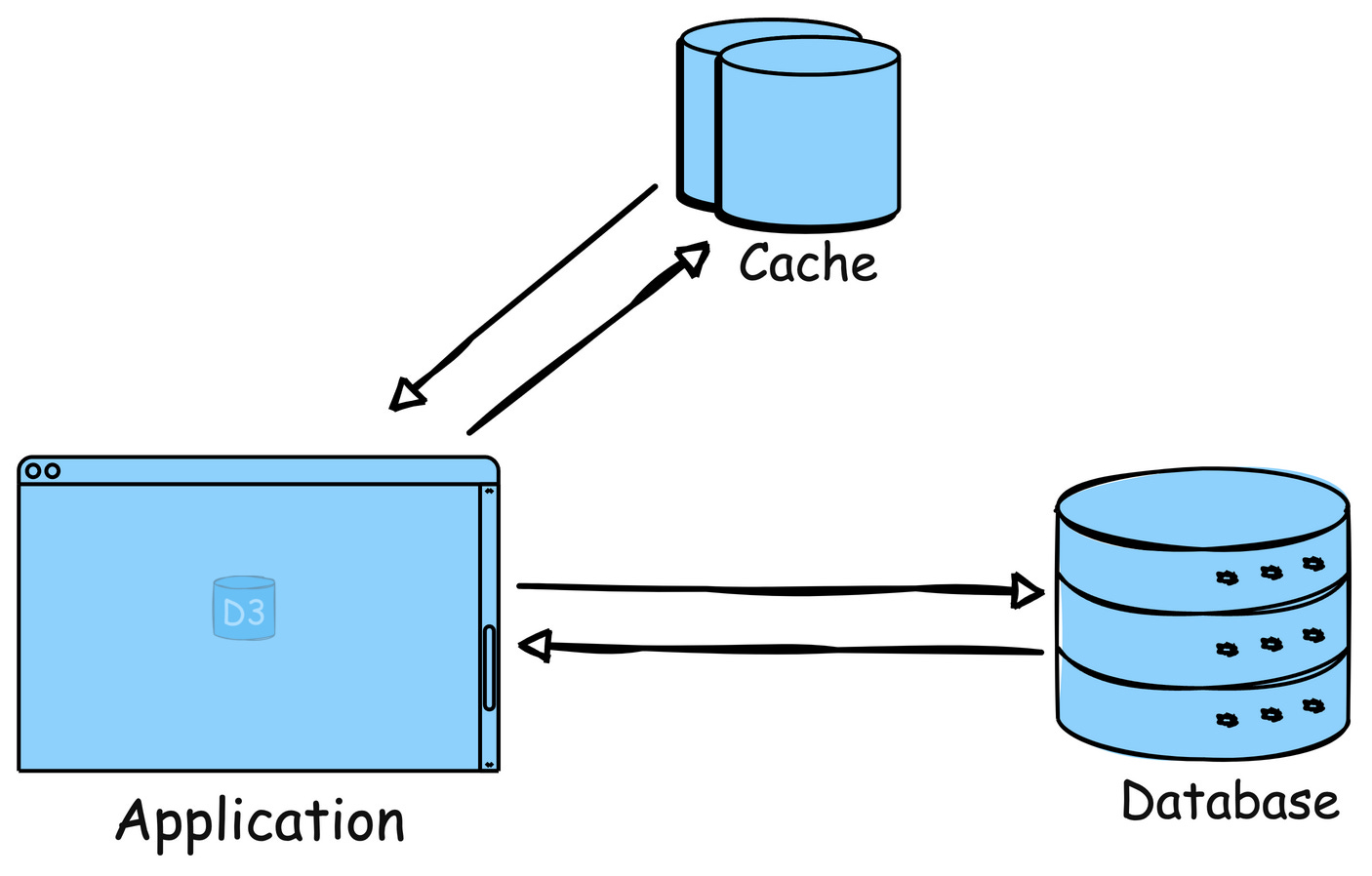
Example: Reddit uses caching to store frequently accessed content like hot posts and comments so that they can be served quickly without querying the database each time
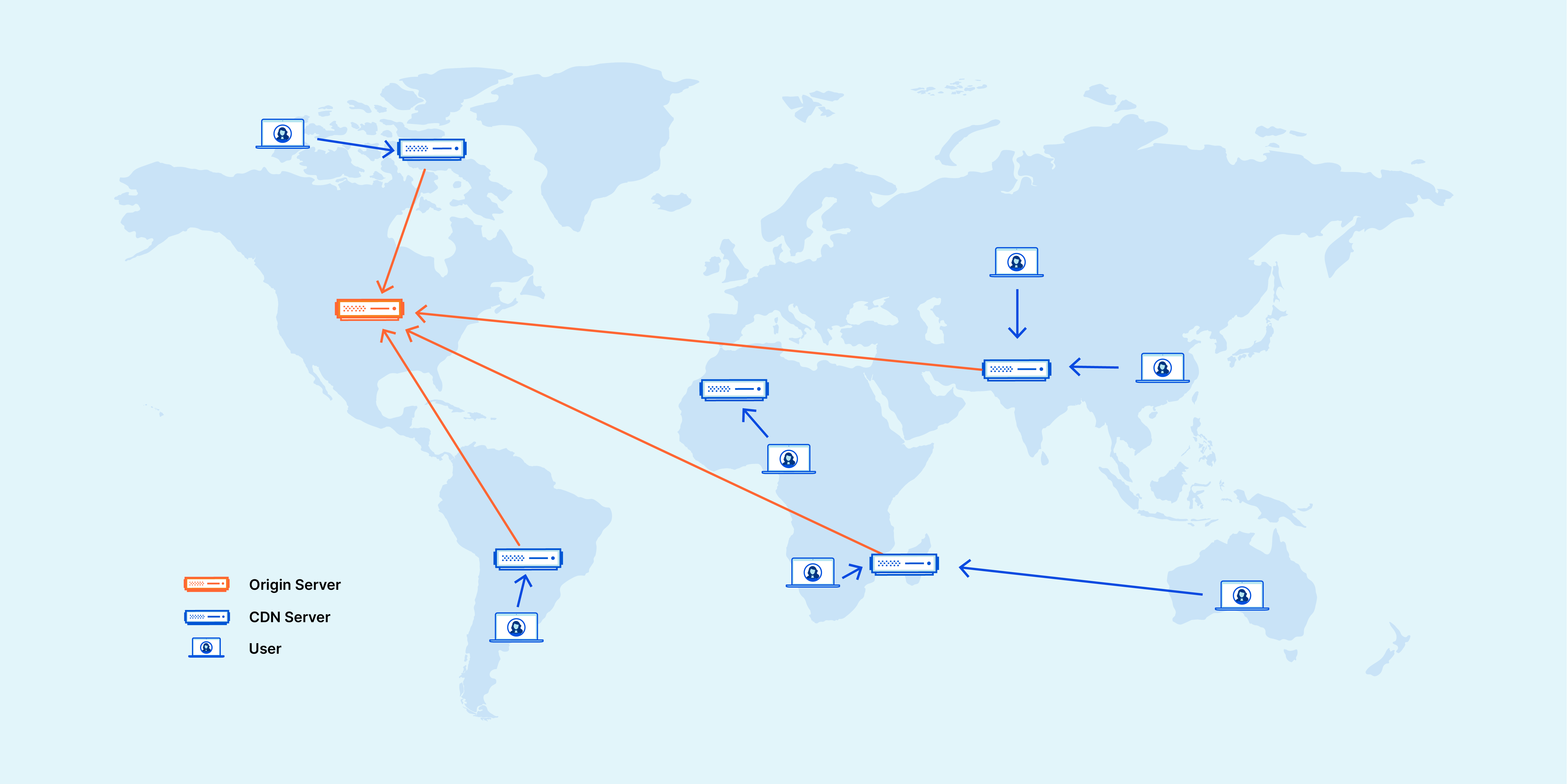
3. Content Delivery Networks (CDNs)
Distribute static assets (images, videos, etc.) closer to users. This can reduce latency and result in faster load times.
Example: Cloudflare provides CDN services, speeding up website access for users worldwide by caching content in servers located close to users.
4. Partitioning
Split data or functionality across multiple nodes/servers to distribute workload and avoid bottlenecks.
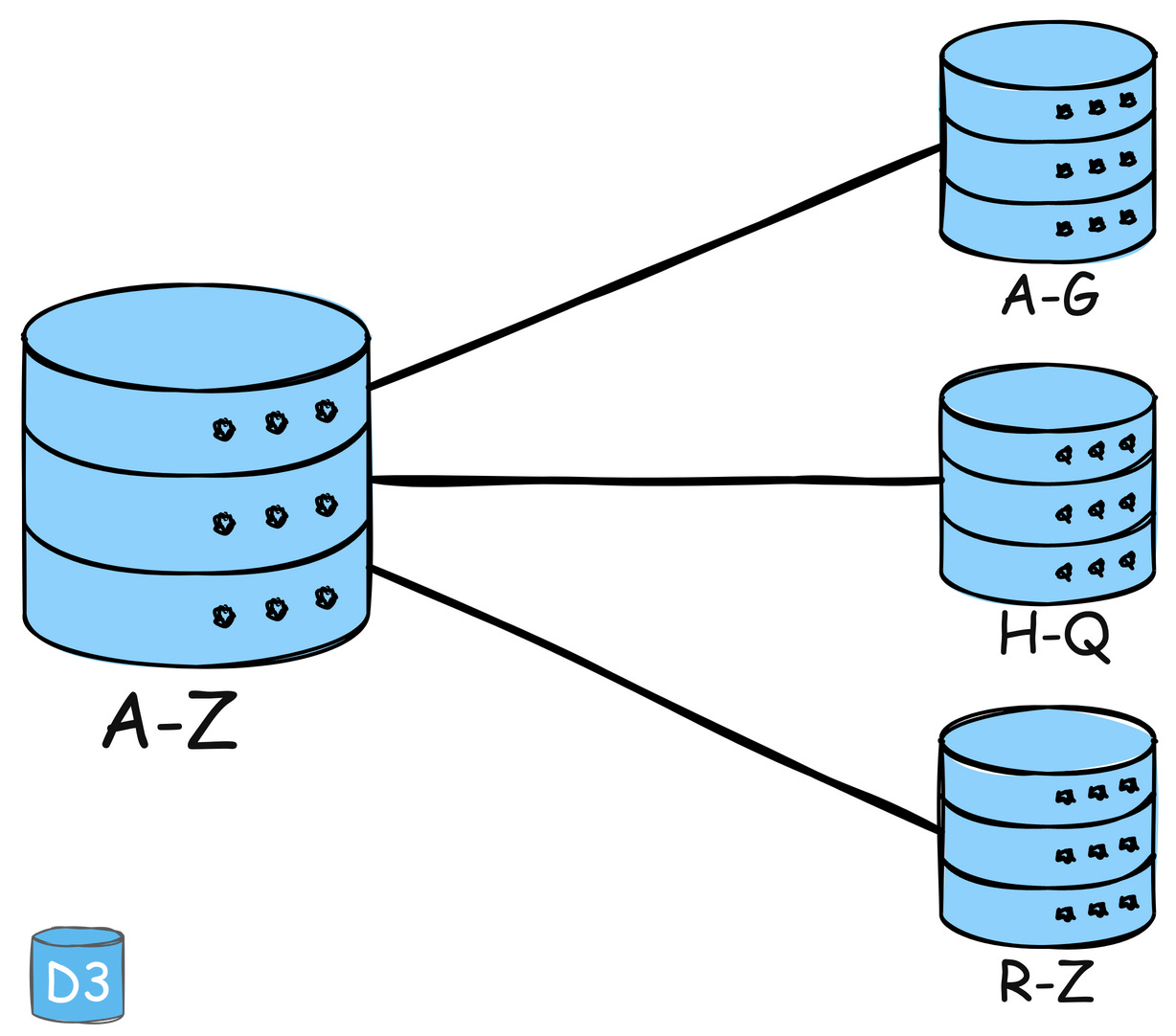
Example: Amazon DynamoDB uses partitioning to distribute data and traffic for its NoSQL database service across many servers, ensuring fast performance and scalability.
5. Asynchronous communication
Defer long-running or non-critical tasks to background queues or message brokers. This ensures your main application remains responsive to users.
Example: Slack uses asynchronous communication for messaging. When a message is sent, the sender's interface doesn't freeze; it continues to be responsive while the message is processed and delivered in the background.
6. Microservices Architecture
Break down your application into smaller, independent services that can be scaled independently. This improves resilience and allows teams to work on specific components in parallel.
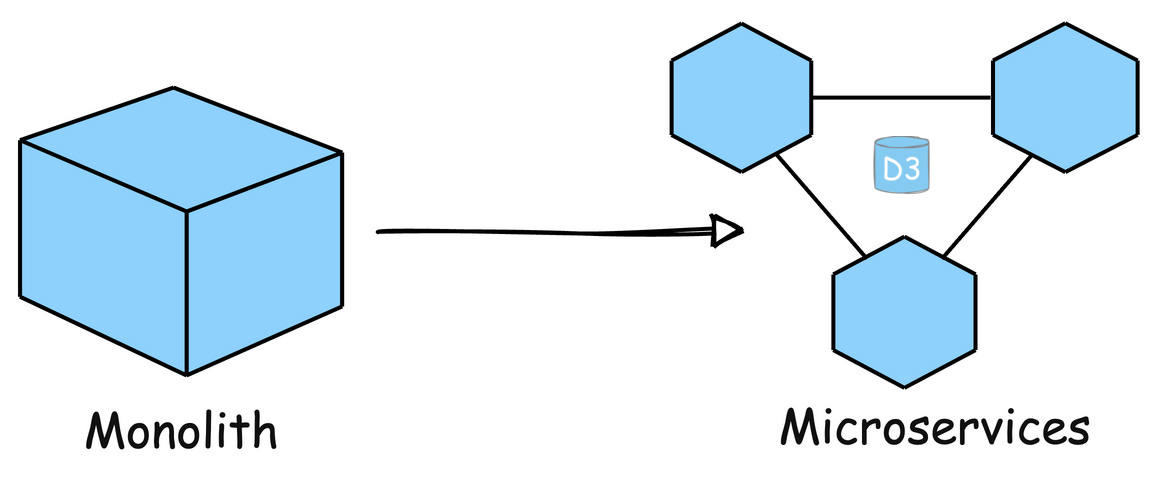
Example: Uber has evolved its architecture into microservices to handle different functions like billing, notifications, and ride matching independently, allowing for efficient scaling and rapid development.
7. Auto-Scaling
Automatically adjust the number of active servers based on the current load. This ensures that the system can handle spikes in traffic without manual intervention
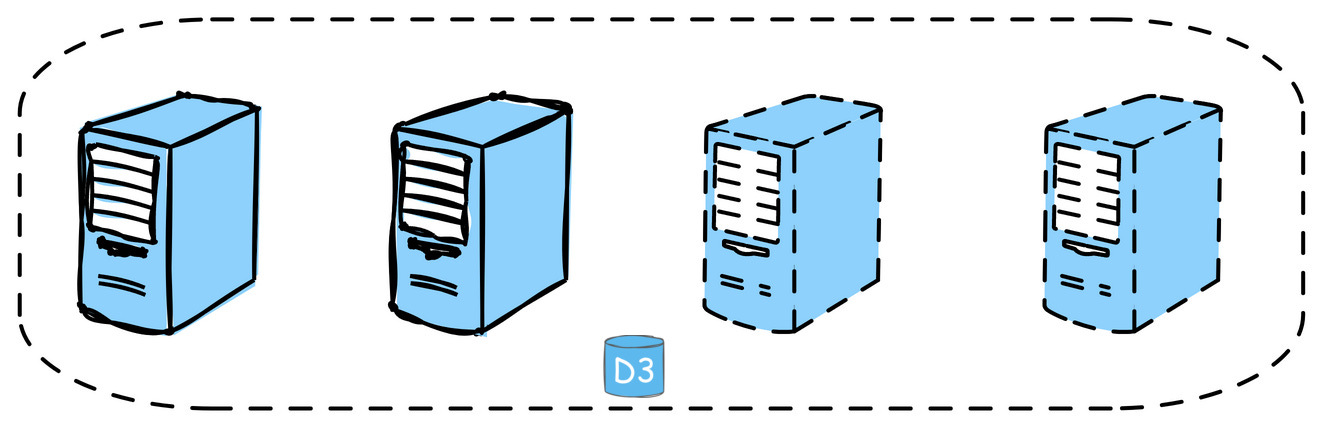
Example: AWS Auto Scaling monitors applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost.
8. Multi-region Deployment
Deploy the application in multiple data centers or cloud regions to reduce latency and improve redundancy.
Example: Spotify uses multi-region deployments to ensure their music streaming service remains highly available and responsive to users all over the world, regardless of where they are located.
Challenges and Trade-offs in Scalability
Challenges and trade-offs in scalability are important considerations when designing and implementing scalable systems. Some of the key challenges and trade-offs include:
- Cost vs. Scalability: Scaling a system often involves adding more resources, which can increase costs. There is a trade-off between the cost of scaling and the benefits gained from improved performance and availability.
- Complexity: As systems scale, they tend to become more complex. This complexity can make it harder to maintain and troubleshoot the system, leading to increased operational overhead. Consistency vs. Availability: In distributed systems, there is often a trade-off between consistency (ensuring that all nodes have the same view of the data) and availability (ensuring that the system remains operational even if some nodes fail). Achieving strong consistency can impact scalability, as it may require more coordination between nodes.
- Latency vs. Throughput: There is often a trade-off between latency (the time it takes for a request to be processed) and throughput (the number of requests that can be processed per unit of time). Optimizing for low latency may reduce throughput, and vice versa.
- Data Partitioning Trade-offs: Partitioning data can improve scalability by distributing it across multiple nodes. However, choosing the right partitioning strategy involves trade-offs, such as balancing the size of partitions, minimizing data movement, and ensuring data locality.
- Trade-offs in Consistency Models: Different consistency models, such as strong consistency, eventual consistency, and causal consistency, offer different trade-offs in terms of scalability, availability, and performance. Choosing the right consistency model depends on the specific requirements of the application.
- Trade-offs in Caching: Caching can improve performance and scalability by reducing latency and load on backend systems. However, caching introduces trade-offs, such as the trade-off between cache consistency and cache hit rate.
Thank you so much for reading. If you found it valuable, consider subscribing for more such content every week. If you have any questions or suggestions, please email me your comments or feel free to improve it. YouTube Resource (gkcs)

Written by Rahul Aher
I'm Rahul, Sr. Software Engineer (SDE II) and passionate content creator. Sharing my expertise in software development to assist learners.
More about meRate Limiting
- #system-design
- #aws
- #lld
Rate limiting runs within an application, rather than running on the web server itself. Typically, rate limiting is based on tracking the IP addresses that requests are coming from, and tracking how much time elapses between each request. The IP address is the main way an application identifies who or what is making the request. A rate limiting solution measures the amount of time between each request from each IP address, and also measures the number of requests within a specified timeframe. If there are too many requests from a single IP within the given timeframe, the rate limiting solution will not fulfill the IP address's requests for a certain amount of time.
What’s the Difference Between Throughput and Latency?
- #system-design
- #aws
- #lld
Latency and throughput are two metrics that measure the performance of a computer network. Latency is the delay in network communication. It shows the time that data takes to transfer across the network. Networks with a longer delay or lag have high latency, while those with fast response times have lower latency. In contrast, throughput refers to the average volume of data that can actually pass through the network over a specific time. It indicates the number of data packets that arrive at their destinations successfully and the data packet loss.